Research Showcase
On this page, I will showcase some of the research research projects that I have worked on, as well as ongoing projects. I am both interested in collaboration and consulting on these matters so feel free to reach out if any of this is of your interest.
Model-Based Clustering in Latent Factor Analysis
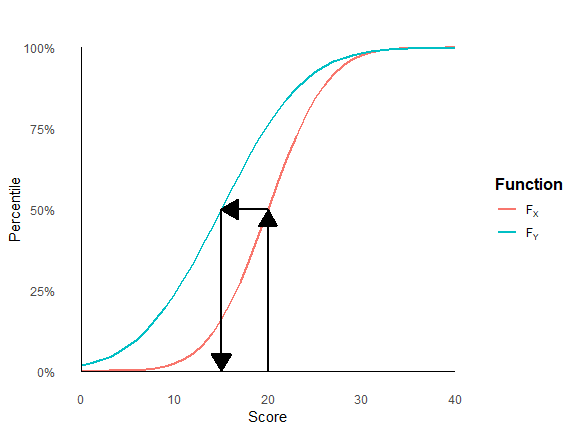
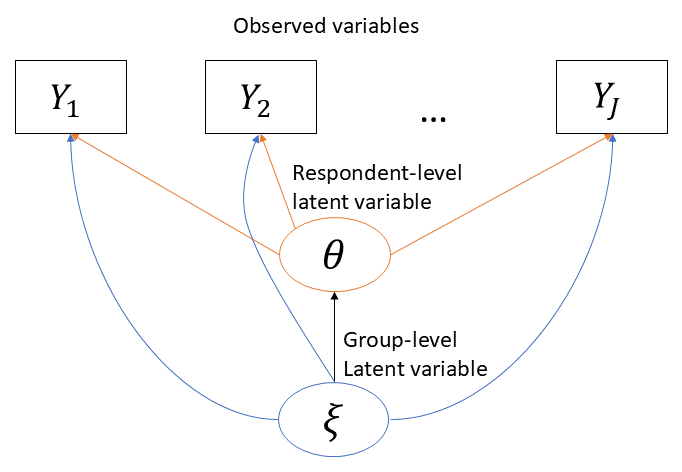
Ensuring fairness and interpretability in tools like surveys, questionnaires, and educational tests is essential. Differential Item Functioning (DIF) analysis is a technique used to explore whether different groups respond differently to specific items, even when they have the same overall ability or trait level. Traditional DIF methods require prior knowledge of comparison groups and unbiased items, but this information is not always available. To address this, me and my collaborators have developed a flexible statistical framework that can identify hidden group differences and adjust for biased items without needing predefined groups or unbiased items. This method can be applied across various domains, from evaluating student assessments to understanding consumer preferences in market research. We have proposed a regularized estimator and an efficient EM algorithm to identify these hidden patterns, making it possible to ensure fairer assessments and more accurate insights. The model is described through a path diagram below.
The proposed framework is currently being extended in a number of directions, including statistical inference for the proposed regularised estimator. Please let me know if you are working with survey-type data, possibly with large numbers of measurement units (respondents/costumers/students etc) and variables, and are interested in multi-group analysis.
Respondent-level Change-Point Detection in Latent Factor Analysis
I have developed statistical methodology for multi-stream change-point detection in latent factor models. A motivating example was the detection of individual-level response-style changes due to, for example, time pressure in high-stakes educational testing or lack of motivation in low-stakes testing or in questionnaires. To better model the underlying response process, we introduce a novel statistical methodology where a baseline latent factor model is fused with a change-point model. The baseline model captures normal item response behaviour, and the post-change model captures the aberrant behaviours (e.g., item responses under time pressure). The change-points are treated as latent variables whose change-point probability depends on item parameters and, possibly, the latent construct level of the respondent. We propose an efficient Expectation-Maximization algorithm that estimates the baseline and change-point model parameters simultaneously.
In the figure below, respondent-level change-points (i.e., the change in response behaviour) are illustrated with gray circles. The task is to identify the change-point for each respondent and simultaneously estimate all of the model parameters.

Interpretable Unsupervised Learning
Modern data analysis frequently involves reducing a high-dimensional dataset to a lower-dimensional one that retains the same key characteristics. To this end, researchers often use exploratory factor analysis to uncover the underlying structure in multivariate data. A key focus in this area is developing methods to enhance the interpretability of the models. My research explores new approaches to improving factor analysis by introducing novel techniques for rotation and regularized estimation. These methods aim to achieve more accurate and computationally efficient results, particularly when dealing with sparse data structures. I also work on model selection and inference procedures to ensure the robustness and consistency of these methods. The applications are diverse, ranging from personality testing and mental health assessments to recommendation systems in marketing.
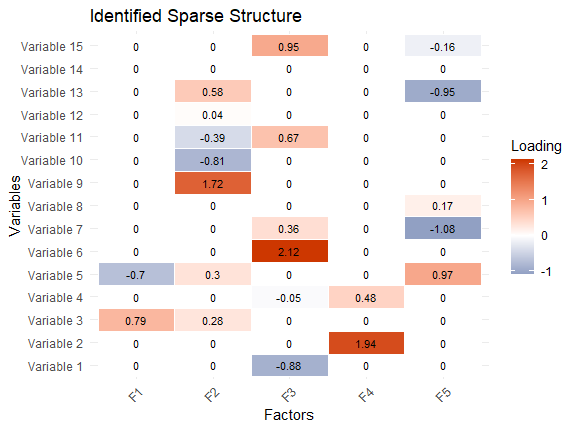
Score Equating: A Statistical Alignment Problem
Score equating is the statistical process of aligning scores from different assessments, tests, or measurement instruments to ensure they are comparable on a common scale. This process adjusts for variations in difficulty, form, or context across different versions of an assessment, allowing scores to be interpreted consistently. Beyond educational testing, score equating can be applied in various fields such as educational and psychological measurement, market research and health surveys, where measurements from different tools or time points need to be standardized, ensuring that the results are equivalent and comparable across diverse conditions. It is fundamentally about finding a transformation or relationship that preserves the meaning of scores across different scenarios.